python简易爬虫
本文共 1909 字,大约阅读时间需要 6 分钟。
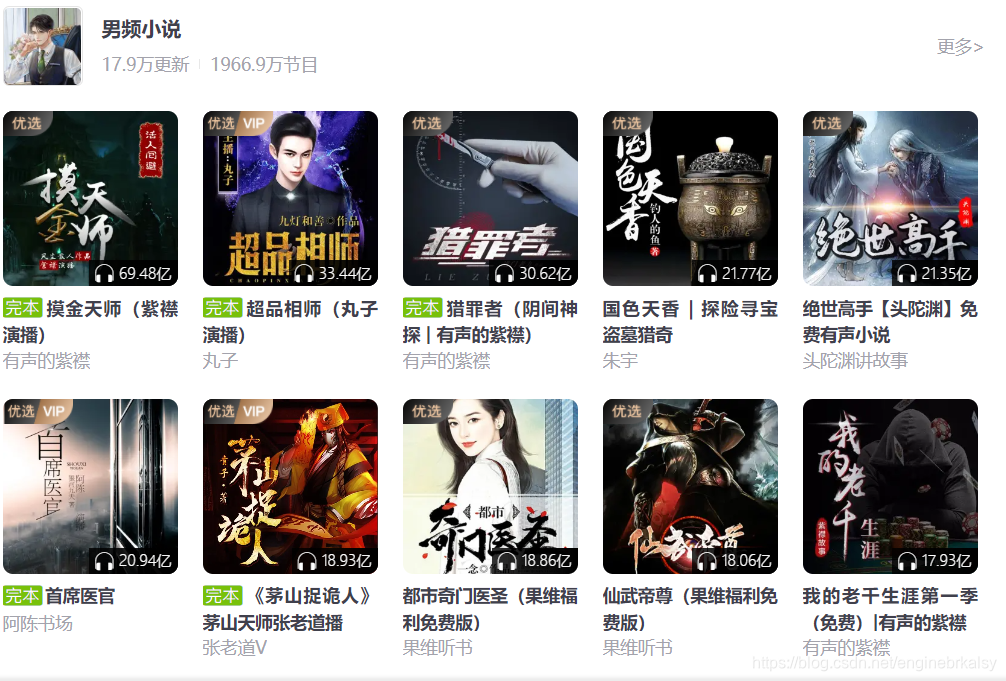
爬取喜马来雅男频小说这几本
import requestsimport reimport csvheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','Cookie':'testcookie=yes; Hm_lvt_bc3b748c21fe5cf393d26c12b2c38d99=1619717328; Hm_lpvt_bc3b748c21fe5cf393d26c12b2c38d99=1619717328; JJEVER=%7B%22fenzhan%22%3A%22noyq%22%7D; smidV2=20210430012854effd865c944ddc429b0c481dfef3f31d0035c72a77d581610'}class ximalaiyaSpider: def getSource(self): # 获取url数据 # 目标url url = 'https://www.ximalaya.com/channel/7/' resp = requests.get(url, headers=headers) resp.encoding='utf-8' # print(resp.content.decode('utf-8')) return resp.text def parseSource(self): content =self.getSource() r =re.match(r'.*?( - .*?
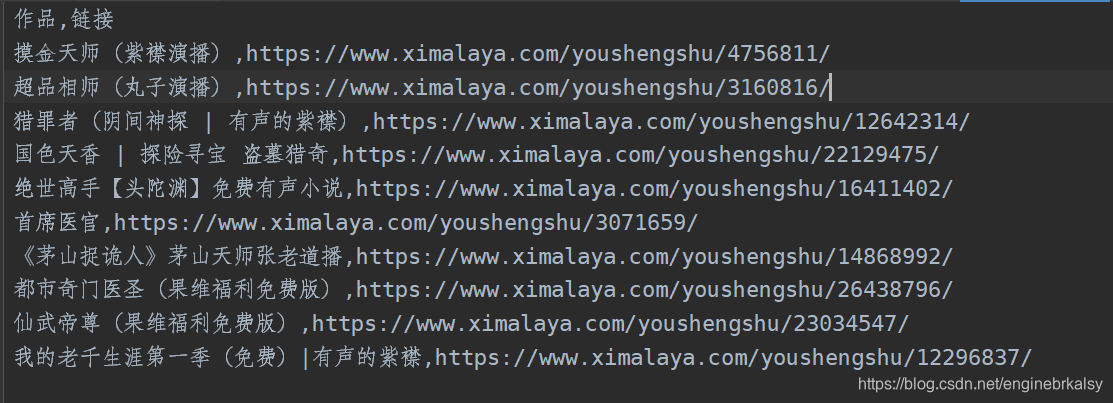
csv结果:
转载地址:http://brun.baihongyu.com/
你可能感兴趣的文章
mysql 主从 lock_mysql 主从同步权限mysql 行锁的实现
查看>>
mysql 主从互备份_mysql互为主从实战设置详解及自动化备份(Centos7.2)
查看>>
mysql 主键重复则覆盖_数据库主键不能重复
查看>>
Mysql 优化 or
查看>>
mysql 优化器 key_mysql – 选择*和查询优化器
查看>>
MySQL 优化:Explain 执行计划详解
查看>>
Mysql 会导致锁表的语法
查看>>
mysql 使用sql文件恢复数据库
查看>>
mysql 修改默认字符集为utf8
查看>>
Mysql 共享锁
查看>>
MySQL 内核深度优化
查看>>
mysql 内连接、自然连接、外连接的区别
查看>>
mysql 写入慢优化
查看>>
mysql 分组统计SQL语句
查看>>
Mysql 分页
查看>>
Mysql 分页语句 Limit原理
查看>>
MySQL 创建新用户及授予权限的完整流程
查看>>
mysql 创建表,不能包含关键字values 以及 表id自增问题
查看>>
mysql 删除日志文件详解
查看>>
mysql 判断表字段是否存在,然后修改
查看>>